
_5.jpg)
繼前篇 讓想像的場景成真:單靠文字描述就能生成AI圖像的Midjourney 後,對於AI圖像生成是否感到意猶未盡呢?玩了幾次Midjourney後,喜歡動手修改參數或更改生成邏輯的朋友們可能漸漸坐不住了,有沒有自由度更高的方式呢?
今天要介紹的 Disco Diffusion,是由MIT(麻省理工學院)與 ISL(Intel Intelligent Systems Lab英特爾智能實驗室),所共同釋出版權的的研究項目,一樣可以用一段文字的情境敘述,就可以生成AI圖像;最棒的是,它是開源的,任何人都可以免費取得程式碼並修改內容與生成參數,並調試成專屬於自己風格的AI生成引擎。
Disco Diffusion 也擁有自己的Discord社群 (https://discord.gg/jR6zuvDY3S),可以在上面與其他使用者交流,甚至還有提供技術支援,簡直是保姆級的免費大禮包,如果你對生成式藝術有興趣、又有點程式底子的話,非常推薦玩玩看。
前期準備
開始前,你需要準備一台電腦、以及一組Google帳號。程式直接運行在google的雲端,所以電腦的配備其實不是特別要求。接下來,到這個網址取得Disco Diffusion的程式碼,記得「複製到雲端硬碟」後才能編輯:
https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb

1. Set Up
捲動畫面到標題寫有 1. Set Up 的位置,並將它展開,它會協助檢查你的環境有沒有符合程式運行的需求,從1.1~1.6把play按過一輪就可以了。如果你是第一次用這台電腦運行,可以檢查看看;如果確定你的環境ok的話,直接跳過這一part也是可以。
2. Diffusion and CLIP model settings
這裡可以選擇你要選用那些模型(model)來生成圖像,譬如分辨率、CLIP的模型選用....等等。如果對於AI、自然語言處理有一定認識的朋友,可以按照自己的喜好來進行選擇。需要注意是,同時選擇越多,對於電腦效能的負擔就越多,可能要考慮到你目前裝置可負荷的運算量來斟酌。如果不認得這些選項也沒有關係,維持預設值的效果也挺不賴。
3. Settings
終於來到有趣的部份,也就是圖像的設定。這裡為初次接觸的新手朋友們列出最基本的設定選項:
Basic Settings > batch_name: 設定待會產出圖片的資料夾名稱
Basic Settings > steps: 圖片更新次數,數字設越大圖片越銳利
Basic Settings > width_height: 產出的圖片長寬 (單位:px)
Init Settings > init_image: 如果有準備參考的圖片素材,可以在這裡設定
Extra Settings > intermediate_saves: 半成品的儲存張數
Prompts: 在這裡以文字輸入想要呈現的畫面、風格、色調等
4. Diffuse!
display_rate: 設定每幾張圖顯示一次刷新
n_batches: 設定這一次執行將會出幾張圖
開始算圖
上面的設定都做完後,我們就可以開始執行程式,讓AI來幫忙畫圖了。到上方工具列選取執行階段 > 全部執行 (Ctrl+F9),畫面會要求你授權Google權限,選取同意後,就可以等收圖了。
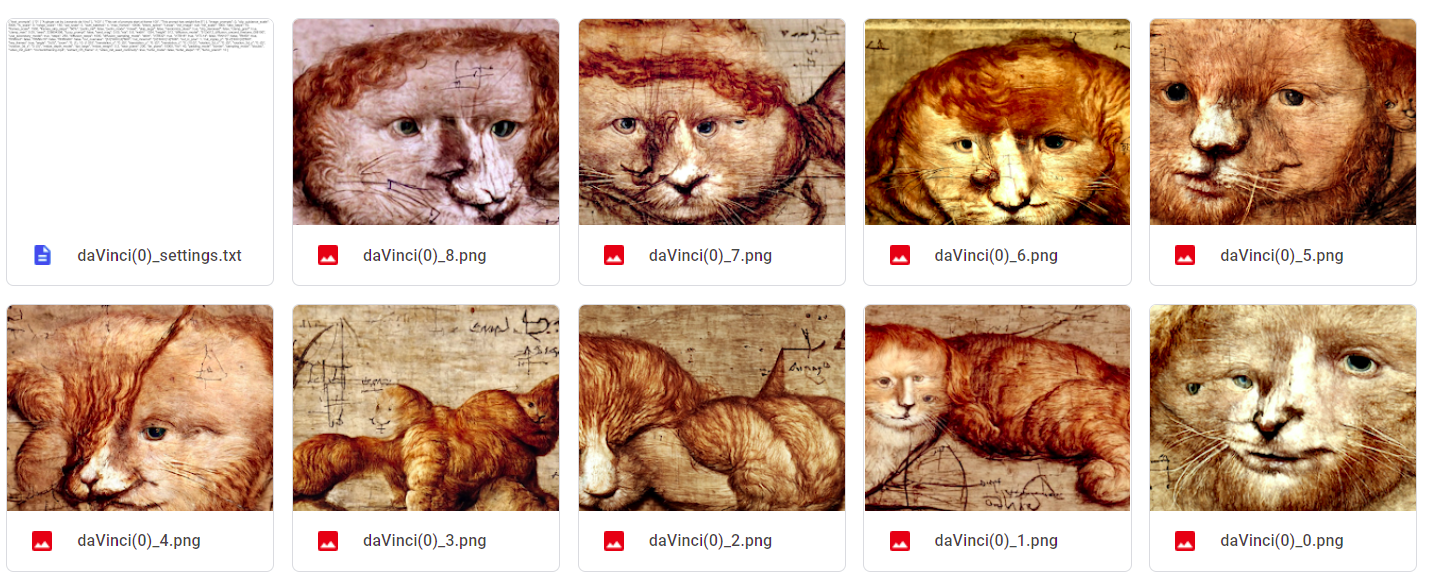
算出來的圖片,可以到google drive中的AI文件夾 > Disco_Diffusion > images_out 找到。另外,程式也會以文字檔的形式,附上執行當時所使用的所有設定,方便下次產圖時當作參考:








關於作者

嗨,我是 Bonnie Chou,謝謝你讀完這篇文章。 這裡記錄我在科技業、新創與專案管理的實戰心得,希望這些內容,能讓你不只獲得技巧,也讓思路更清晰,面對選擇更有把握。 提供 顧問服務、專案合作、創業諮詢、職場關係諮詢、企業與團體內訓。













